提示工程发展生态与典型工具论文简述(工程发展及演化受到哪些因素的制约)
提示工程并非空中楼阁,它的每一次范式转移都建立在坚实的学术研究和日益完善的工程化工具之上。理解其背后的关键论文和主流工具,是提示工程师构建自身知识体系、提升实践效率的必经之路。本章将首先回顾几篇奠基性与前沿性的研究论文,它们定义了提示工程的核心技术路径;随后,我们将全面梳理并对比2025年市场上主流的提示工程工具与平台,包括中国国内的代表性产品,为读者提供一份清晰的“军火库”地图。
一、典型研究与代表性论文简述
学术研究是推动提示工程发展的引擎。以下几篇论文,从不同维度深刻地影响了我们与大型语言模型交互的方式,至今仍是理解高级提示技术的理论基石。
1.1思维链(Chain-of-Thought, CoT):开启模型推理的“内心独白”
核心贡献:Google Brain在2022年发表的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》是提示工程发展史上的一个分水岭。其核心发现是,通过在提示的示例中加入解决问题的中间推理步骤,可以显著提升大型语言模型在算术、常识和符号推理等复杂任务上的表现。CoT将提示从简单的“输入-输出”映射,转变为引导模型进行“输入-思考-输出”的认知过程。
2025年视角与简评:到了2025年,CoT已经从一种前沿技巧,演变为提示工程的标准实践和基础能力。它不再仅仅局限于Few-Shot示例,其Zero-Shot形式(即在提示中加入“Let's think step by step”等魔法指令)已被证明同样有效,并被广泛集成到各类框架和应用中。虽然有研究指出,对于最新、最强大的模型(如GPT-4.1)在处理某些中等难度任务时,其内在推理能力已经很强,显式的CoT带来的边际效益有所下降。然而,对于任何需要多步逻辑、分解复杂问题的场景,CoT及其变体(如思维树Tree-of-Thoughts, ToT)仍然是保证输出质量和可解释性的最可靠手段。它开启了我们引导和观察模型“内心独白”的时代,是后续所有复杂推理技术(如ReAct)的奠基石。
1.2 ReAct:让模型“思考”并“行动”的智能体框架
核心贡献:同样在2022年,Google的研究者在论文《ReAct: Synergizing Reasoning and Acting in Language Models》中提出了一个革命性的框架,将推理(Reasoning)与行动(Acting)无缝结合。在ReAct框架下,模型不再是一个封闭的“语言生成器”,而是一个可以与外部世界交互的智能体(Agent)。它通过生成一种“思考-行动-观察”(Thought-Action-Observation)的循环轨迹,来动态地解决问题。
例如,在回答“目前巴黎的天气如何?”时,模型会先思考(Thought):“我需要查询天气信息”,
然后生成一个行动(Action)指令:search( weather in Paris"),
然后系统将这个指令执行(调用一个天气API),并将结果观察(Observation)15°C, cloudy反馈给模型。
最后,模型基于这个观察,生成最终答案:“目前巴黎的天气是15摄氏度,多云。”
展开全文2025年视角与简评: 如果说CoT让模型学会了“自言自语”,那么ReAct则让模型学会了“动手做事”。到2025年,ReAct框架已经成为所有主流AI智能体架构的理论内核。无论是开源的LangChain、LlamaIndex,还是各大云厂商提供的Agent构建平台,其核心循环都脱胎于ReAct的“思考-行动-观察”模式。这一框架极大地扩展了LLM的应用边界,使其从一个封闭的知识库,转变为一个能够感知和改变数字世界(甚至通过机器人技术改变物理世界)的行动者。ReAct的重要性在于,它为实现通用人工智能(AGI)的“具身智能”提供了一条清晰、可行的工程路径。提示工程师的角色也因此从“对话设计师”进一步升级为“智能体架构师”,需要设计的不再是单个提示,而是包含工具集、规划器和记忆模块在内的复杂智能体系统。
1.3 自动化提示优化(AutoPrompt / APE):让AI自己成为提示工程师
核心贡献:随着提示工程的复杂性日益增加,一个自然而然的想法浮出水面:我们能否让LLM自己来寻找最优的提示?2022年的论文《Large Language Models are Human-Level Prompt Engineers》提出的Automatic Prompt Engineer (APE)框架,系统性地回答了这个问题。其核心思想是,将提示的发现过程本身,形式化为一个搜索问题。APE框架使用一个LLM作为“提示生成器”,来为目标任务生成大量的候选指令;然后,再用这个LLM作为“评分器”,在验证集上评估这些指令的效果,最终选出得分最高的指令作为最优提示。
2025年视角与简评:APE开启了自动化提示工程(Automated Prompt Engineering)的时代,标志着提示工程开始从“手工作坊”迈向“工业化生产”。到2025年,这一思想已经演化并融入到更广泛的LLMOps(大型语言模型运维)实践中。除了APE中使用的简单生成与评分,业界还引入了更复杂的优化算法来搜索提示,例如遗传算法(如GAAPO)、强化学习、贝叶斯优化等,它们能够更高效地在巨大的提示空间中寻找最优解。这些技术在一些定义明确、有清晰评估指标的任务(如文本分类、情感分析、摘要生成)上,已经被证明可以达到甚至超越人类专家手动优化的水平。自动化提示优化并没有完全取代人类工程师,而是将他们从繁琐、重复的“炼丹”工作中解放出来,让他们更专注于定义问题、设计评估体系和处理更具创造性的、开放式的任务。它代表了提示工程领域“元认知”的终极形态——用AI来优化与AI的沟通。
二、代表工具和平台
如果说前沿论文为提示工程指明了方向,那么层出不穷的工具和平台则为其实践铺平了道路。从简单的API交互界面到复杂的应用开发框架,再到专门的监控和安全工具,2025年的提示工程师拥有一个日益丰富的“军火库”。本节将梳理当前生态中最具代表性的几类工具和平台,并以表格形式进行横向对比,帮助读者根据自身需求做出选择。
2.1 核心工具与平台概览
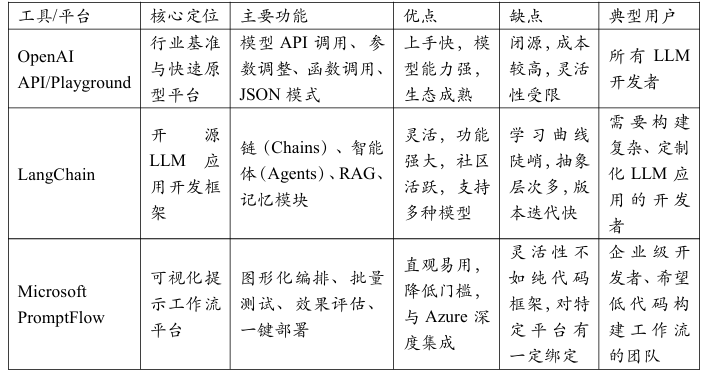
OpenAI Playground / API
定位:事实上的行业起点与基准。OpenAI不仅提供了GPT系列这一强大的基础模型,其Playground和API也成为了无数开发者入门提示工程的第一站。
核心功能:Playground提供了一个即时反馈的交互界面,让工程师可以快速试验不同的提示、角色设定和参数(如Temperature, Top-p)。API则提供了将提示工程产品化的所有基础能力,包括系统提示(System Prompt)、函数调用(Function Calling)和JSON模式等,这些都已成为现代提示工程不可或缺的基础设施。
LangChain
定位:最流行的开源LLM应用开发框架。LangChain的目标是“将大型语言模型与外部数据和环境连接起来”。它通过提供一套标准化的、可组合的组件,极大地简化了构建复杂LLM应用的流程。
核心功能:其核心是“链(Chains)”和“智能体(Agents)”。Chains允许将多个LLM调用或与其他工具的调用串联起来,形成工作流。Agents则基于前述的ReAct理论,让LLM可以动态地选择和使用工具集(如搜索引擎、计算器、数据库)来完成复杂任务。它还提供了对模型I/O、数据检索(RAG)、记忆模块的丰富封装。
Microsoft PromptFlow / PromptCanvas
定位:可视化的、端到端的提示工程工作流平台。PromptFlow(集成于Azure AI Studio)和类似概念的PromptCanvas,旨在将提示工程从代码编写,转变为更直观的图形化流程编排。
核心功能:用户可以通过拖拽节点的方式,构建一个包含提示、Python代码、LLM调用、条件判断等在内的有向无环图(DAG)。这种“所见即所得”的方式非常适合设计和调试复杂的提示链(Prompt Chaining)。它还内置了批量测试、效果评估(A/B Test)和一键部署等功能,打通了从开发到生产的全链路。
Hugging Face Hub + PEFT
定位:AI领域的“GitHub”,模型与数据集的集散地,以及软提示的大本营。
核心功能:Hugging Face Hub托管了数以万计的开源模型,是开发者选择基础模型的重要来源。在提示工程领域,其生态系统中的PEFT(Parameter-Efficient Fine-Tuning)库至关重要。PEFT库实现了包括Prompt Tuning(软提示)、LoRA在内的多种参数高效微调技术。对于希望探索“软提示”或“连续提示”的工程师来说,Hugging Face的生态提供了从训练到部署的全套工具。
NVIDIA Nemo Guardrails
定位:专注于LLM应用安全与合规的开源“护栏”工具包。
核心功能:Nemo Guardrails不直接参与提示内容的生成,而是在用户与LLM之间建立一个可编程的中间层。开发者可以使用一种名为Colang的简单语言,定义三类护栏:话题护栏(如禁止谈论政治)、安全护栏(如过滤不当言论)和程序性护栏(如强制模型按特定流程回应)。它通过拦截和改写用户输入或模型输出来确保对话始终在预设的“安全轨道”上运行。
LangSmith
定位:专为LLM应用设计的可观测性(Observability)与测试平台。
核心功能:由LangChain团队打造的LangSmith,解决了LLM应用调试难、监控难的痛点。它能捕获并可视化每一次LLM调用的完整轨迹,包括输入的提示、模型的输出、Token消耗、延迟、以及Agent的完整“思考-行动-观察”链条。这使得工程师可以像调试传统软件一样,清晰地看到应用内部的每一个环节,快速定位问题。它还支持数据集管理和在数据集上运行评估,是实现PromptOps的关键一环。
国内提示工程平台
定位:深度优化中文语境、紧跟本土市场需求的综合性平台。
核心功能:以深度求索(DeepSeek)、阿里通义千问(Qwen)、智谱AI(GLM)、月之暗面(KIMI)等为代表的国产大模型,在2025年已经形成了强大的生态。它们除了提供对标OpenAI的Playground和API能力外,更在以下方面展现出差异化优势:
中文优化:对中文的理解,包括古文、网络用语、复杂成语和文化背景的把握上,通常优于国外模型。
本土化服务:提供更符合国内开发者习惯的文档、社区支持和云服务集成。
合规性:其平台和服务在设计之初就充分考虑了中国的法律法规要求,为企业在国内部署应用提供了便利。这些平台的提示工程实践与国际主流趋势大体一致,但工程师在使用时需要特别关注其在处理中文特有现象(如歧义、多音字、文化隐喻)时的细微差别和最佳实践。
2.2 工具与平台对比
为了更直观地比较,下表总结了上述各类工具与平台的关键特征:

这个工具生态仍在快速演进,但上述代表已经勾勒出了2025年提示工程师所需的核心能力栈:基础交互能力(OpenAI)、复杂编排能力(LangChain/PromptFlow)、深度定制能力(Hugging Face)、安全保障能力(Nemo Guardrails)和运维观测能力(LangSmith)。
三、提示工程工具深度解析
在了解了主流工具的基本定位后,我们将深入探讨几个在2025年最受关注的提示工程工具和平台,从其核心架构、最佳实践到实际应用案例,为读者提供一份可直接上手的实战指南。
3.1 LangChain与LangSmith:从开发到运维的完整生态
LangChain的深度应用模式
LangChain在2025年已经发展成为一个庞大的生态系统。其核心价值不仅在于提供了一套标准化的组件库,更在于它定义了一种组合式AI应用开发范式。理解这个范式,是掌握现代提示工程的关键。
核心组件架构:
提示模板(Prompt Templates): LangChain的提示模板系统支持变量插值、条件逻辑和部分模板(Partial Templates)。这使得提示可以像软件中的函数一样被复用和组合。

链式调用(Chains):链是LangChain的核心抽象。最简单的链是LLMChain,它将提示模板、LLM调用和输出解析器串联起来。更复杂的链,如SequentialChain,可以将多个步骤串联,其中每一步的输出都成为下一步的输入。
实践案例:构建一个自动化的内容审核与改写链



智能体(Agents)与工具(Tools): 智能体是LangChain中最强大也最复杂的组件。它基于ReAct框架,赋予LLM"决策"能力——根据当前任务动态选择使用哪些工具。
实践案例:构建一个能够查询天气和计算的智能助手


LangSmith:提示工程的DevOps平台
如果说LangChain是“开发框架",那么LangSmith就是“运维平台"。它解决了LLM应用在生产环境中的三大核心挑战:可观测性、可测试性和可优化性。
全链路追踪(Tracing): LangSmith能够捕获并可视化每一次LLM调用的完整轨迹。对于一个复杂的Agent应用,它会展示:
用户的原始输入Agent的每一步“思考"(Thought)每一次工具调用及其返回结果最终的输出每一步的Token消耗和延迟这种透明度使得调试从“猜测"变成了“观察"。数据集与评估(Datasets & Evaluation): LangSmith允许工程师创建和管理测试数据集。每个数据集包含多个测试用例,每个用例包含输入和期望的输出(或评估标准)。
工程师可以在数据集上运行提示的不同版本,并使用自定义的评估器(可以是简单的字符串匹配,也可以是另一个LLM作为Judge)来自动化地评估每个版本的表现,从而实现A/B测试和回归测试。
提示版本管理(Prompt Versioning):在LangSmith中,每个提示都可以被保存为一个独立的"版本"。工程师可以在不同版本之间切换,比较它们的性能,并将最优版本部署到生产环境。这实现了提示的Git式版本控制。
最佳实践:LangChain + LangSmith的完整工作流
开发阶段:在LangChain中快速构建原型,使用LangSmith的Tracing功能进行调试。
测试阶段:在LangSmith中创建测试数据集,对提示的多个版本进行批量评估。
部署阶段:将表现最佳的提示版本部署到生产环境,并通过LangSmith持续监控其在真实流量下的表现。
优化阶段:基于监控数据和用户反馈,迭代优化提示,并通过A/B测试验证改进效果。
3.2 Helicone:专注于提示管理与成本优化的轻量级平台
Helicone是一个在2025年迅速崛起的提示工程工具,它的核心理念是"轻量级、专注、易集成"。与LangChain这样的"全家桶"不同,Helicone专注于解决两个核心痛点:提示的版本管理和API调用的成本优化。
核心功能:
提示组合与变量管理:Helicone提供了一个直观的Web界面,让工程师可以在其中创建和管理提示模板。这些模板支持变量插值,并且可以被组织成"提示库"。
最重要的是,Helicone将提示与代码解耦。工程师不需要在代码中硬编码提示内容,而是通过一个简单的API调用,根据提示的ID或名称来动态加载提示。这使得提示的修改和迭代可以在不重新部署代码的情况下完成。
版本控制与即时部署:每次修改提示,Helicone都会自动创建一个新版本。工程师可以为不同的环境(开发、测试、生产)指定不同的提示版本,并通过一键切换来进行灰度发布或回滚。
成本监控与优化:Helicone作为一个“AI Gateway"(AI网关),位于你的应用与OpenAI/Anthropic等模型提供商之间。所有的API调用都会经过Helicone,这使得它能够:
实时统计每个提示、每个用户、每个功能模块的Token消耗和成本。
提供可视化的成本分析报表,帮助识别“成本黑洞"。
支持缓存功能:对于相同的输入,直接返回之前的结果,避免重复调用,从而节省成本。
实践案例:使用Helicone管理多版本提示并监控成本
假设你正在开发一个客服聊天机器人,需要对不同类型的用户问题使用不同的提示。
在Helicone中创建提示:
提示名称:customer_support_greeting
版本1.0内容:“你好!我是AI客服助手,请问有什么可以帮助您的?"
版本2.0内容(更友好):“您好呀!我是您的专属AI助手,很高兴为您服务!请告诉我您遇到了什么问题,我会尽力帮您解决~"
在代码中调用:
在Helicone Dashboard中:
查看两个版本的使用情况和用户满意度(通过集成的反馈机制)。
发现版本2.0的用户满意度更高,但Token消耗也增加了15%。
基于ROI分析,决定在高价值用户群体中使用版本2.0,在普通用户中继续使用版本1.0。
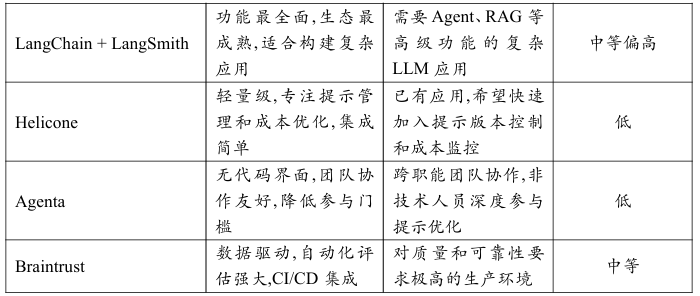
3.3 Agenta与Braintrust:新一代LLMOps平台的代表
Agenta:面向团队协作的提示实验平台
Agenta是一个开源的LLMOps平台,其设计哲学是让“非技术人员也能参与提示工程"。它提供了一个无代码/低代码的界面,让产品经理、内容运营等角色可以直接创建、测试和优化提示,而无需编写代码。
核心特性:
Playground with Variants:Agenta的Playground允许用户同时创建一个提示的多个“变体"(Variants),并在同一个界面中并排比较它们的输出。这极大地加速了提示的迭代过程。
Human-in-the-Loop Evaluation(人在回路的评估):Agenta支持邀请团队成员对不同提示变体的输出进行人工打分和标注。这些人工评估数据可以与自动化评估指标(如相似度分数)结合,形成更全面的评估体系。
一键部署与API生成:一旦确定了最优的提示变体,Agenta可以自动将其封装为一个REST API,供应用调用。这使得提示的“生产化"变得极为简单。
Braintrust:数据驱动的提示优化平台
Braintrust将自己定位为“LLM应用的持续集成/持续部署(CI/CD)平台"。它的核心是一个强大的评估引擎和实验管理系统。
核心特性:
自动化评估流水线(Automated Evaluation Pipeline):Braintrust允许工程师定义一套评估标准(Evaluators),这些标准可以是:
基于规则的(如检查输出是否包含特定关键词)
基于模型的(如使用GPT-4作为Judge来评估输出质量)
基于人工标注的黄金数据集
每次提示或模型发生变化时,Braintrust会自动在测试集上运行评估,并生成详细的性能报告。
实验对比与统计显著性检验:Braintrust不仅展示不同提示版本的平均得分,还会进行统计显著性检验,告诉你“版本B比版本A好"这个结论是否在统计上可靠,还是仅仅是随机波动。
与CI/CD工具集成:Braintrust可以与GitHub Actions、GitLab CI等工具无缝集成。每次代码提交或Pull Request,都会自动触发提示的评估,并将结果反馈到代码审查流程中。这实现了真正的“提示即代码"(Prompt as Code)理念。
对比总结:
3.4 中国本土平台的创新实践
在2025年,中国的提示工程生态已经形成了独特的创新路径。除了前文提到的大模型提供商(如DeepSeek、Qwen),还涌现出一批专注于提示工程工具链的本土创业公司和开源项目。
代表性平台:
字节跳动的Coze(扣子): Coze是一个面向国内开发者的AI应用开发平台,其核心是“Bot构建器"。它提供了可视化的界面,让用户可以通过配置提示、选择插件(工具)和设定工作流,来快速构建一个AI聊天机器人或智能助手,并一键发布到飞书、微信等平台。
创新点:
插件市场:提供了丰富的预构建插件(如天气查询、日程管理、文档搜索),降低了工具集成的门槛。
知识库集成:支持上传企业内部文档,自动构建RAG系统。
多轮对话管理:内置了对话状态管理和上下文记忆功能。
开源项目Dify:Dify是一个开源的LLMOps平台,被誉为“中国版的LangChain"。它提供了从提示编排、应用开发到部署监控的全链路能力。
创新点:
可视化工作流编排:类似于PromptFlow,但更加轻量和易用。
多模型支持:无缝支持OpenAI、Anthropic以及国内所有主流大模型。
企业级功能:内置了团队协作、权限管理、日志审计等企业所需的功能。
本土平台的差异化优势:
语言与文化适配:对中文的细微语义、文化背景和表达习惯有更深的理解和优化。
合规性:在数据安全、内容审核等方面,天然符合中国的法律法规要求。
生态集成:与国内的云服务(阿里云、腾讯云)、办公软件(飞书、钉钉)、社交平台(微信)有更紧密的集成。
服务响应:本地化的技术支持和社区,响应速度更快。
通过对这些工具和平台的深入理解和灵活运用,提示工程师可以构建起一个高效、可靠、可扩展的LLM应用开发与运维体系,真正将提示工程从“艺术"推向“工程"。
本指南共计分为“提示工程概述、大模型与提示交互机制、发展生态与典型工具/论文简述、高级提示工程技术、特定场景应用实践、评估与优化、前沿趋势与未来展望”七大部分内容。上述文章仅为「发展生态与典型工具/论文简述」的部分内容摘选。
完整版指南,请扫描下方二维码或点击【阅读原文】下载。